
{{sindex}}/{{bigImglist.length}}
专访 | 如何使用ML-Agents教机器人踢足球?

Unity Machine Learning Agents Toolkit(简称ML-Agents)工具套能帮助用户在 Unity 中轻松入门强化学习(RL)。ML-Agents 本身带有多种样例环境和模型架构,可让用户利用现成的环境和架构上手 RL,再通过调整超参数来测试和改进结果模型。所有这些都毋须新建 Unity 场景或导入资源,且初期不涉及任何编程。
ML-Agents:
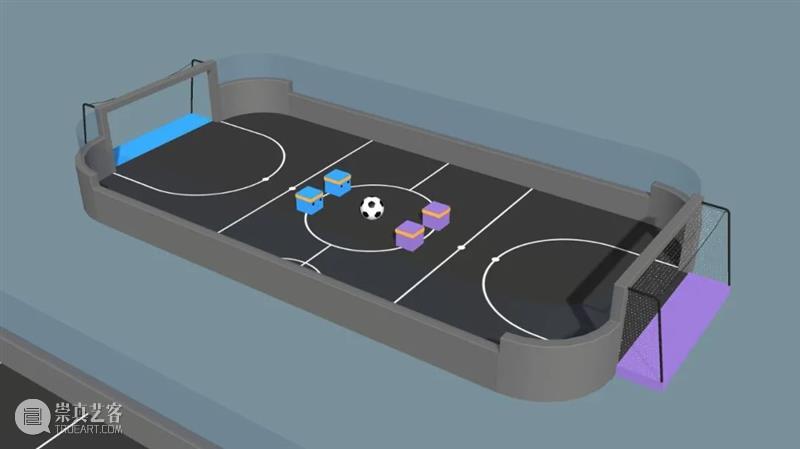
本文介绍的项目由日本公司 Ghelia Inc. 创立,他们使用了 ML-Agents 的 soccer 训练环境来训练智能代理踢足球。训练出的 RL 模型随后被部署到了索尼的 toio 机器人上,在真实世界中踢起了足球。这是一个用 ML-Agent 训练机器人、从“虚拟到现实”的绝佳实例。
我们采访了 Ghelia 的 CEO 兼总裁清水亮,创新和品牌战略办公室的首席程序员布留川英一及创新部经理 Masatoshi Uchida,来了解该项目的灵感。请在下文中了解公司怎样使用 ML-Agents Toolkit 来训练一个真实机器人踢足球,及高尔夫球在场景中的作用。

请问是什么启发了你们呢?
Ghelia 是一家专注于强化学习应用的公司。Ghelia 的创始人北野弘明在索尼任职期间创办了 Robocup Soccer 足球赛,并开发出了 AIBO 机器人。我们的团队曾制作过一个空气曲棍球演示,但过于繁杂的部件使其变得不够轻便。接着为了向客户们解释强化学习的概念,我们开始讨论制作另一个便于展示的演示场景。鉴于 ML-Agents 已经有了一个足球训练环境,我们完全可以用轻便小巧的索尼 toio 机器人来开发一个足球游戏,游戏甚至有可能被病毒式传播。
你们是怎样将 ML-Agent 模型移植到真正的机器人上的?

实机运行的硬件配置是?
我们使用一个高尔夫球来代表足球,并将其涂成红色以提高辨识度。不可思议的是,我们仅用一部 iPhone 就能完成足球的探测,控制所有八个机器人(这是一场四对四的足球比赛),再使用 ML-Agents 模型进行推导。

你们是如何设置奖励的?
期限,代理们都各自为政,只顾自己进球,于是我们试着给个人进球设置了负面奖励,但这又导致了守门员不会去主动防守球门。而如果为运球设置积极奖励,两队又只会来回运球,不会积极射门,基本上就是在拖时间。最后,我们决定把奖励设置为进球得一分,被进球则扣一分。
项目中最具挑战的地方在哪里?
有时实机机器人并不会像模拟的那样行动,其背后原因有时让人捉摸不透。比方说,如果机器人在一个稍微倾斜的地板上运动时,有时会导致推导失败;另外,如果球的反弹与模拟不同,机器人也无法做出训练好的反应。并且,机器人对摄像机位置的要求十分严苛,需要达到毫米级的精度,这使得每次线下活动的镜头调整异常困难。在每一次大型修改后,模型还需要三天左右的训练时间来适应,我们总共进行了约六次的训练环节来实现如今的成果。

虚拟机器人在相互碰撞时不会有太大的影响,但真正的机器人相撞可能会引发意外。你们是如何解决这个问题的呢?
在 ML-Agents 的演示里,智能代理在进球后会自行回到原位站好,但这一步对真正的机器人来说没这么简单。问题在于,仅靠强化学习很难避免 toio 机器人相撞。最初我们试图为避免相撞设立奖励,但最终还是找到了一种机智的解决方法。
对于那些想在项目中用上机器学习的 Unity 创作者,你有什么建议?
AI,特别是深度学习是让人痴迷,但人们尚未充分理解它。除非亲手尝试过,否则你将无法欣赏技术的美和复杂度,当个半桶水可不光彩,所以我们鼓励全球 Unity 开发者亲自上手 AI 技术。我想特别指出机器学习非常有趣,而 Unity ML-Agents 工具能帮你轻松地上手或整合机器学习到项目中。







{{flexible[0].text}}


Find Your Art
{{pingfen1}}.{{pingfen2}}
吧唧吧唧




{{item.publisher_name}}



加载更多
已展示全部
延伸阅读
{{item.publisher_name}} 发布了 文章
{{item.title}}
{{layerTitle}}
使用微信扫一扫进入手机版留言分享朋友圈或朋友
长按识别二维码分享朋友圈或朋友
{{item}}
编辑
{{btntext}}
继续上滑切换下一篇文章
提示
是否置顶评论
取消
确定
提示
是否取消置顶
取消
确定
提示
是否删除评论
取消
确定
登录提示
还未登录崇真艺客
更多功能等你开启...
更多功能等你开启...
立即登录
跳过
注册

 分享
分享